It's about time for our first official development update since the launch of our platform! Thanks to our developers' hard work, we've got some significant updates to our platform to improve the user experience, with a focus on data scientists. Let's take a closer look at all of them.
A better graph view, easier to navigate and manipulate
Let’s start with what’s staring us in the face. We made a significant overhaul to the design of our graph view!
What used to be one big cluster is now more logically grouped in different mini clusters. This completely changes how you can interact with your data environment, allowing you to group related components or microservices thanks to Kubernetes Namespaces and making it easier to find what you need.

We also made the graph a lot more stable, allowing you to move resources with more precision. You might see the occasional jittery node, but that’s only because the graph is now constantly being updated in real-time. No more pressing F5!
To accompany the new way it updates, we added a minor visual update, namely colour-coding the nodes to see which ones are updated quickly, updating, or experiencing an error.
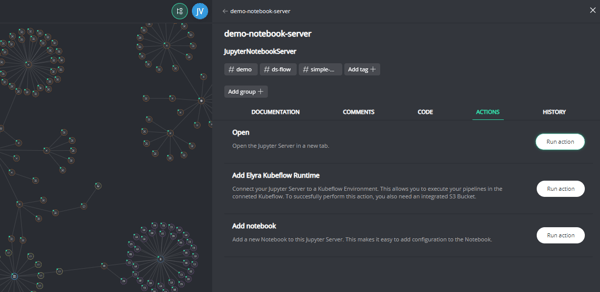
Not only is the graph view a bit clearer, providing better oversight, and more stable. It’s also easier to configure. We made it easier to set up many connections between resources and configs and add actions to many resources to do what you want quickly.
For example, when selecting a database, you can now access it with the single click of a button instead of searching for the IP address.
More resources, with a focus on data science and ML
When it comes to adding functionality, we focussed on the data science flow, specifically on easy integration of Machine Learning. To facilitate this, we concentrated on a couple of things. Let’s do a quick rundown.-
Elyra: our custom Jupyter Lab has a new supported function, and we do mean it when we say brand new because the software was only released a couple of months ago. Elyra is an ingenious solution to build pipelines from Jupyter notebooks. Just drag and drop and connect the dots to create your machine learning pipelines!
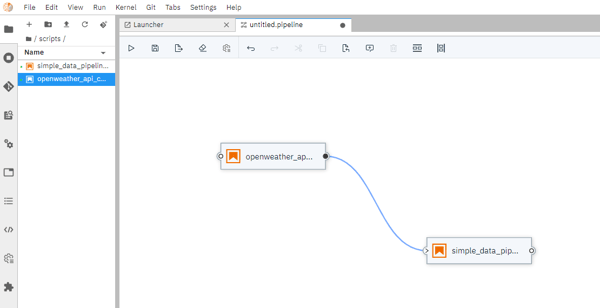
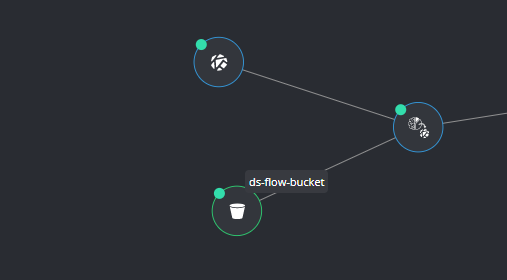
- Kubeflow runtime: to run your pipeline with sufficient resources, we suggest using the integrated Kubeflow runtime. We made the integration into Tengu as easy as possible. This requires storage as well, which leads us to buckets.
- S3 MinIO Buckets: to support both Elyra and Kubeflow runtime functions, we integrated a storage resource. These work perfectly with your Elyra pipelines executed in the Kubeflow runtime.
With these three new functionalities, you can set up an ML flow from start to finish. Combine your Jupyter Notebook scripts into a pipeline with Elyra, execute it in Kubeflow runtime and store your data in an S3 MinIO bucket.
Need some code? Git over here
Last but not least…
Elyra isn’t the only new thing in our custom Jupyter Lab, and you can now directly import GitHub repositories into your workspace!
Now you can work on notebooks, scripts and configs through GitHub and import those straight into your pipeline, all confirming with the git protocol, ensuring easy collaboration and tons of existing resources you can use.
Are you interested in how all these integrations make for an easy and seamless data science project flow?
Discover our DataOps use cases and demo videos here!


