If you’re a fan of data, these are exciting times for you. It wouldn’t be an understatement to say that this is the era of big data and its application in analytics, business intelligence, machine learning and artificial intelligence.
The hype these technological advancements are receiving is well deserved. When applied, these technologies can aid businesses in immeasurable ways. Think of fraud detection, predictive analysis, and other techniques that help you with finding magical sweet spots in the market. Big data analytics is even able to predict and mitigate natural disasters, but let’s stick to the business side for now.
In other words, if you’re not on AI, BI, or ML by now, you’re lagging behind according to almost every industries’ standards.
Having all these fancy tools, every company investing in data-driven decision making must surely be ahead by now right? Well no not really,
it looks like most big data projects failed.
According to a recent study of Forrester, only 22 % of companies see a return on their investment in data and technology. Twenty-two, that’s less than 1 out of 4 companies. Moreover, Gartner reported that about 60 % of the data projects were never finalised, and 80 % of the data projects didn’t succeed in delivering useful data.
What happened? We can look at the hype cycle, coined by research firm Gartner, for answers. It teaches us an important lesson, that after the initial hype comes the trough of disillusionment, in the form of disappointment.
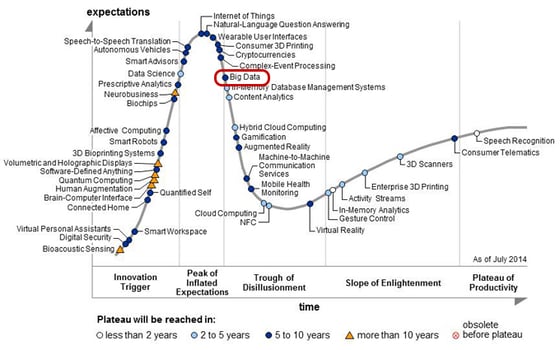
Fig. : Gartner's Hype cycle of emerging technologies of 2014, the moment Big Data passed its peak.
Let’s take a closer look at why so many projects disappoint.
Through the trough of disappointment
Many businesses joined the big data revolution. While this is something I applaud -being data-driven is a sign of an innovative company- it was mostly half-assed.
Don’t get me wrong, they had great intentions, and some made a significant difference.
What I meant is that, while intentions were noble, most data projects were either too ambitious or rushed without proper or support. For the sake of clarity and brevity, I’ll split the reason up in these two factors.
The first factor is very straightforward: Data science isn’t magic.
It’s consistently either misunderstood or overestimated. While it can make an arguably otherworldly difference when applied with love (more on that later), it’s not the be-all and end-all of decision-making, but a guideline or feedback. Certainly not a tool or platform that you invest in and suddenly starts printing money.
On the other hand, without proper investment you’re not getting very far either.
This brings me to the second reason why data projects fall flat when it comes to tangible returns. If you want to go scuba diving, climb a mountain, or do just about any endeavour, you’re going to want to bring some decent equipment right? Yet, when it comes to investments in data, there’s a lot of hesitation.
This is understandable, doubt is inherent to the new nature of data-driven decision-making, but at the same time the downfall of most projects. Trying to scale your data projects is a smart move, but without investing in a great foundation your data teams are working with their hands tied to their back.
DataOps, no longer a set of best practices but a necessity
Every new technique needs refining. Without trying something new once in a while we’d be nowhere, but those first few years are tarnished by failed experiments. After all, the second mouse catches the cheese (by observing what went wrong with the first mouse).
Enter DataOps, a process-oriented methodology used by data profiles to improve the quality and efficiency of analytics. While it began as a set of best practices, compiled in a manifesto, it has evolved into a new and independent approach to data analytics.
Put in simple terms, DataOps decreases the time it takes to get from data to insight with continuous integration and continuous deployment of data and analytics (otherwise known as the CI/CD principle), an agile approach to improve response time, and statistical process control or SPC to maintain constant data and analytics quality thanks to efficient monitoring.
By applying these methods, the time from data to insight can be greatly reduced. Simply put less work for more results. For example: a couple of years ago a data team had to spend 80 % of their time collecting, cleaning and preparing data, setting up environments for their analytics, connecting everything... I could keep going, but I’m pretty sure you get the idea. Getting an answer to any simple question with big data used to be a hassle.
As DataOps evolved, so did the technology supporting it, with easier data integration and constant quality control through automation as a result. Whatever the project may be, you can be sure implementing DataOps methods and technology will improve the ROI by cutting down the costs and time needed to gain the same (or better) insights.
Conclusion: start asking the right data questions.
Let’s recap, big data is here to stay and yes, it’s the new oil. But just like extracting oil it’s not a simple process with immediate results. If you want to boost your results, try refining and more efficient methods, like DataOps.
By now it’s no longer a question ‘will you use data’, data is everywhere and why waste what's all around us? The question moves towards ‘what are the goals you want to achieve with data, and what’s the most efficient way of achieving them?’
----------------------------
Curious to how you should achieve your goals? Check out our blogs on data strategy.
or get in touch with us and let’s see how you can apply DataOps principles to your data endeavors.


