You’re back! This is part 2 of a blog series about polyglot persistence. If that word doesn’t ring a bell, I highly recommend checking out part 1 here to get started. In this blog, we’ll dive deeper into how polyglot persistence can be made practical.
In the last part, we established that polyglot persistence leverages different storage solutions in your organization for different use cases in order to improve overall performance. But the major drawback is complexity. So why would you even get started with polyglot persistence?
Mapping the complexity
Well, the truth is that most organizations today (probably even yours) already are in a state of polyglot persistence without realizing it. Think about it, how is your organization doing its bookkeeping? Probably using some tool. Do you have an ERP system? Do you have a CRM? Do you have a database somewhere? A data warehouse maybe? Bluntly said, any software solution you have as an organization retains data in some way. The question, therefore, comes down to, now that we’re in an age of polyglot persistence, how will you handle the complexity that comes with it? In other words, how will you allow applications to use all this data in a simple but effective way?
The first thing you need to know is how many data sources your organization has, what data they contain, what that data means, and how they’re related to each other. This information is usually contained within a data catalogue. You can achieve this with data governance platforms like Collibra to achieve, but if you don’t want to invest in a new platform right away, a shared document will work fine as a starting point. Data governance platforms also give you additional benefits to help you keep the catalogue up to date and take care of data quality, data control, and security processes, but for the purpose of this blog, we’ll limit data governance to the data catalogue.
There is a lot of good material online that can help you construct a data catalogue, but I want to focus on one specific thing you need to think about when evaluating your data sources: data availability. A lot of software solutions might contain some amazing data for your organization to use, but is it available to you? The data storage in the software might not be available outside of the application or tool itself. It might be designed to keep data locked in or there might just not be a way of extracting the data in an automated way. This is an important thing to check when building your data catalogue, but also when evaluating new software solutions your organization considers. Luckily, a lot of developers are opening up access to the data within, through export functionality or APIs. Even cloud-based solutions often have some way of extracting the data for you to use in your organization.
OK, so now you have a data catalogue and know what data you can use. Let’s get to it!
Single Version of the Truth
There are three approaches to dealing with polyglot persistence. The main idea behind the first two approaches is to unify data access as if the polyglot persistence doesn’t exist for applications that are using the company’s data. This is often referred to as a Single Version of the Truth (SVOT), a Single Source of Truth (SSOT), or a Golden Record store (GR). The third approach is purely aimed at operational systems.
The first approach is to explicitly build this SVOT as a new data store. The figure below shows a high-level architecture of this approach.
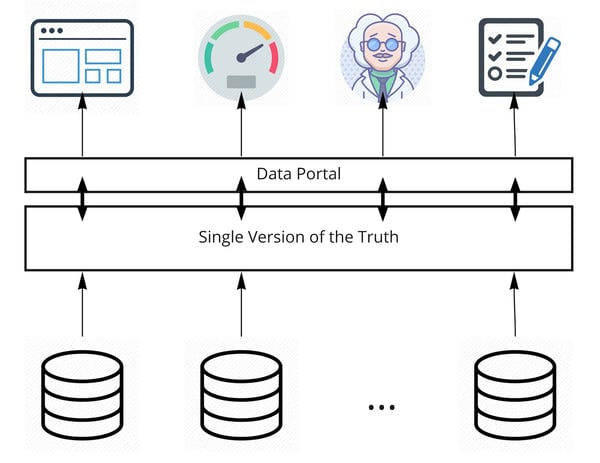
Figure 1: Explicit Single Version of the Truth
It’s obvious that this approach requires a lot of storage since we’ll be duplicating data from the original source into our new SVOT. This might sound familiar since the well-known data lakes are a solution that is built on this approach. However, depending on the use case, other solutions exist as well. For example, if the use case is purely analytical towards a business intelligence platform, this SVOT could be a data warehouse.
If you remember our first part, you might be wondering, the entire idea and benefit of polyglot persistence was the optimisation of performance and now we are introducing a new layer, with additional delay, between applications and data. We, therefore, need to make sure that the delay we introduce with this approach is less than just putting everything in one database (without the original sources). The way we ensure this is through knowing how data will be used by applications and optimizing the data model of our SVOT to serve these queries. This could even include pre-calculating certain values to help our applications be as efficient as possible. Designing the data model is a whole thing in itself and would take us too far away from the architectural level that we are covering in this blog, but I might do another series on this in the future.
The second approach is very similar to the first approach, in that applications still access the data as if it was a centralized single data source, but the data is not stored as such. In other words, the applications see a single data source, but it’s a virtualization of the concept (aka data virtualization). The data remains in its original source as we translate the queries from applications in real-time to the different data sources. The figure below illustrates this approach.
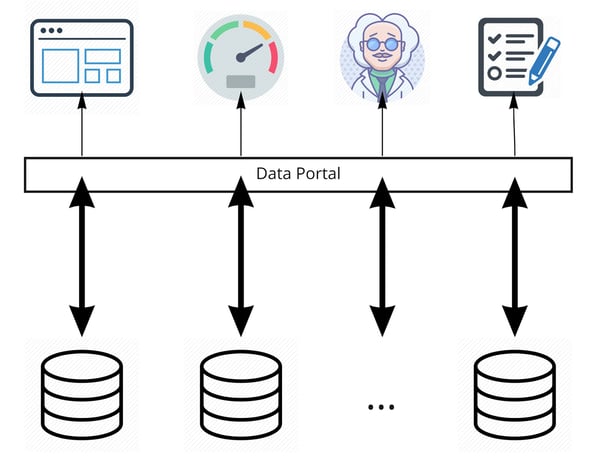
Figure 2: Data virtualization
We can immediately see that this approach will not use the vast amount of storage required in the first approach. However, all query responses are built in real-time. This immediately exposes one of the most important parameters when choosing between the approaches: if queries by the applications are highly complex, data virtualization will create too much latency to be effective and an explicit SVOT (first approach) should be considered. In order to achieve data virtualization, you have a lot of dedicated platforms out there, but you could also define an internal API in your organization and manage it yourself. The options are yours.
Of course, as with many things, hybrid solutions between explicit SVOTs and data virtualization exist, and once again, the solution that will work best for you is heavily dependent on your use case. The question you need to ask yourself over and over again is ‘what data is being used repeatedly’, and in what format. Those datasets are prime candidates for precomputed data sets for your SVOT. If any other data sets remain outside of the SVOT, they can be added through the implicit second approach.
Complexity Schmomplexity
It all seems like this is a lot of hassle with a lot of variables, but when your organization wants to start using data to fuel operations and/or analytics, doing nothing just isn’t an option. There is one caveat to this, which brings us to the third approach.
The third approach to polyglot persistence in an operational context is to basically do nothing about it. If your case is about exchanging operational data between a limited number of systems that won’t change towards the future, you can perfectly build and manage direct data flows between those systems. If you’re feeling fancy, you could even do this through a messaging system or data bus. The main difference in this approach is that we are not shielding any of the data sources (i.e. polyglot persistence). You still need to know what data is stored where and build data flows according to the technology used for that data source. Yet no, or very limited, the delay is introduced between data exchanges.
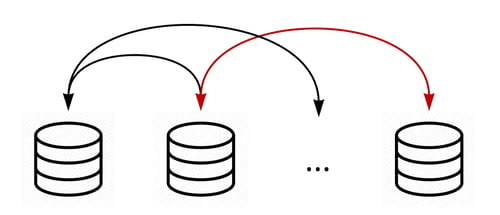
Figure 3: Direct data flows between operational systems
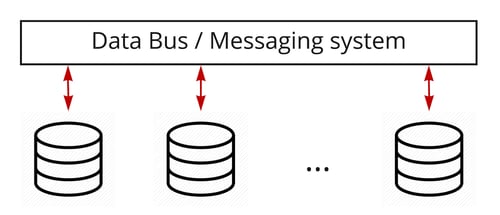
Figure 4: Data flows between operational system through data bus / messaging system
All together now
In reality, all the previously mentioned approaches are often combined in some way to achieve the best results. For example, to power a BI tool, we need to build a data warehouse with pre-calculated values for dashboards (first approach). We also have a front-end application that needs data out of an API to share with customers and partners (second approach). Finally, some operating systems are time-bound and require real-time updates that need to be streamed from other sources (third approach). The figure below details such a data architecture.
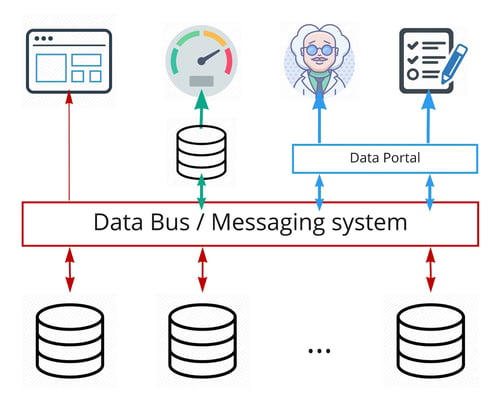
Figure 5: High-level architecture of the three approaches combined (1st: Green - 2nd: Blue - 3rd: Red)
Rome wasn’t built in a day, and neither should an architecture like this be. It is however important to note that organizations need to think about how they want to use data in a sustainable way given the complexity they are confronted with in a polyglot persistence age.
Best of luck, and if you want some more help, feel free to reach out!
TL;DR polyglot persistence is here, whether we like it or not. There are however two approaches that we can take to deal with the resulting complexity and one to just accept the complexity for operational purposes. After building a data catalogue, we can either explicitly or implicitly build a Single Version of the Truth for our applications to use or directly connect all data sources to each other for data exchanges. And like many things, the best solution is probably somewhere in between all those approaches.


