You wouldn’t eat soup with a fork, now would you? Why? Because it isn’t the right tool for the job. You might get some soup in your mouth from time to time, but in general, it’s not an efficient way to get it down. So why are we still forking our data?
In this 2-part blog, I want to talk about how data is often used and how it should be used instead. This first part will focus on polyglot persistence and what it means and where it came from, while the second part will dive into making it practical. Let’s dive in!
On the evolution of databases
Before we get into semantics, we need to have a little history lesson🧐. From the beginning of time, or rather the beginning of computer science, relational databases have been the go-to way of storing data. A relational database represents data as tables (or 'relations'), consisting of columns and rows. The freedom you had in storing data in your organisation was limited to which vendor you would use and how you would organise the data in the tables (i.e. the data model). As a side-note, another term you probably heard to refer to relational databases is SQL databases. SQL, or 'Structured Query Language', is the recognised standard language we communicate with relational databases, which is why the two terms are used as equivalents.
However, when the age of big data rolled around, we quickly realised relational (or SQL) databases were no longer cutting it. Said, the speed at which data sets were growing outpaced the speed at which we could upgrade our computer (server) running our relational database. So instead of using one big computer (or server), we started using several smaller servers clustered together. The idea is that all those smaller servers act like one large server, but there is no theoretical limit to how large your server can become (since you can keep on adding servers to the cluster). Therefore, the age of big data also introduced the age of distributed computing and storage, i.e. storage and computing across a cluster of servers.
The problem for relational databases was that they did not do well in a clustered environment. Crucial performance was lost, and the door was opened for an entire generation of non-relational databases born in this distributed environment. We refer to these databases as 'NoSQL' databases or technologies. The 'No' actually stands for 'not only' (confusing, I know), which means that SQL/relational databases are also part of the NoSQL group (even more confusing, I know).
Allow me to explain: the explosion of new database technologies also triggered a high degree of differentiation, making different databases more suitable for different use cases or data models. In this explosion of the NoSQL movement, it also quickly became clear that there was still a place for relational (or SQL) databases, but in specific use cases and not as a solution-fits-all. That's why SQL is also part of NoSQL.
To SQL or NoSQL
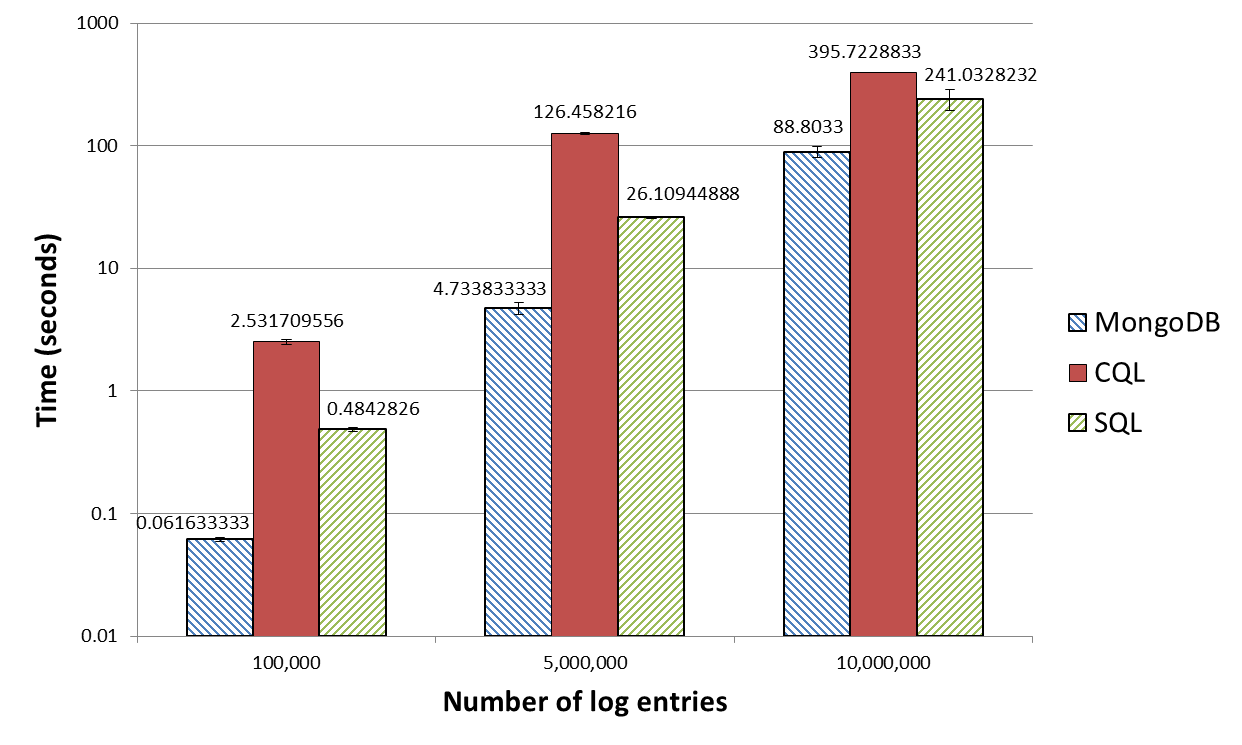
For this simple data set with 10 million entries, you can see over 300 seconds difference in response time between MongoDB (88.80 seconds) and Cassandra (CQL - 395.72 seconds). In other words, the results tell us that to retrieve the same data, Cassandra takes about 300 seconds or 5 minutes (!) longer than MongoDB. A significant impact, especially if you need to run this multiple times during the day. MongoDB and Cassandra are popular examples of NoSQL database technologies, but they are very different. This means that the results should not be interpreted that Cassandra is bad. Cassandra is not the ideal database technology for the test use case we used.
And > Or
So, when building our modern application or architecture, we need to map our use case onto our storage solution to ensure we get the best performance. However, today's applications and organisations often have more than one use case to cover. We could decide on the storage solution that gives us the most performance overall, sacrificing performance in specific parts of our application. Or we could use different databases for the different use cases of our application or architecture, optimising the data performance of our application in every use case. One application would then store their data in two or more database technologies, a situation often referred to as polyglot persistence.
In essence, polyglot persistence is the opposite of pushing everything into one system (e.g. the all-ruling ERP system 😉). It uses different storage solutions for the different use cases in your application or organisation to improve performance. The major drawback? Complexity! It would be best to support different query languages to communicate with the different databases and support those databases in your organisation, etc. How do you manage that complexity? That is our subject for the next part!
TL;DR: polyglot persistence is a situation where one application uses two or more database technologies. Born out of the NoSQL movement, it offers better performance in applications and data architectures but additional complexity.


