Suppose that we want to install an Apache Hadoop cluster with 3 Hadoop Slaves. On top of that we deploy Spark, which can be used for processing the data stored on HDFS and Zeppelin to visualize the data after it has been processed.
Normally the next challenge would be to find a sys admin to help you with this challenge. And these are typically the guys/girls in high demand with not much time left.
Experienced Big Data Engineers know that setting up and prepping an infrastructure such as this will take at least a few days. And for less experienced people, who will be fighting with unforeseen issues almost every minute, it can take even weeks.
But imagine that you would be able to do it yourself and it can be done almost in an instant?
Setting up Big Data Infrastructures and frameworks are basically logical tasks which could be automated. So why is nobody doing this today?
Open-source communities are there to solve problems like this. Since 2014, university students from Belgium have been working on an automation framework for Big Data which allows anyone to deploy a Big Data solution in an automated way. The open-source platform (Tengu), available on GitHub, deploys the components by using automation scripts called "Juju charms".
Deploying a Spark Bundle
The platform launches services and tasks following logical steps written in those charms which are kept up-to-date by the community. Charms are available for any type of microservice such as setting up a VPN, deploying a Hadoop cluster, initiating Spark for data processing, deploying a graph etc.. When the charm is done with its work, a circle appears on the screen showing the component is set up and the right connections are made.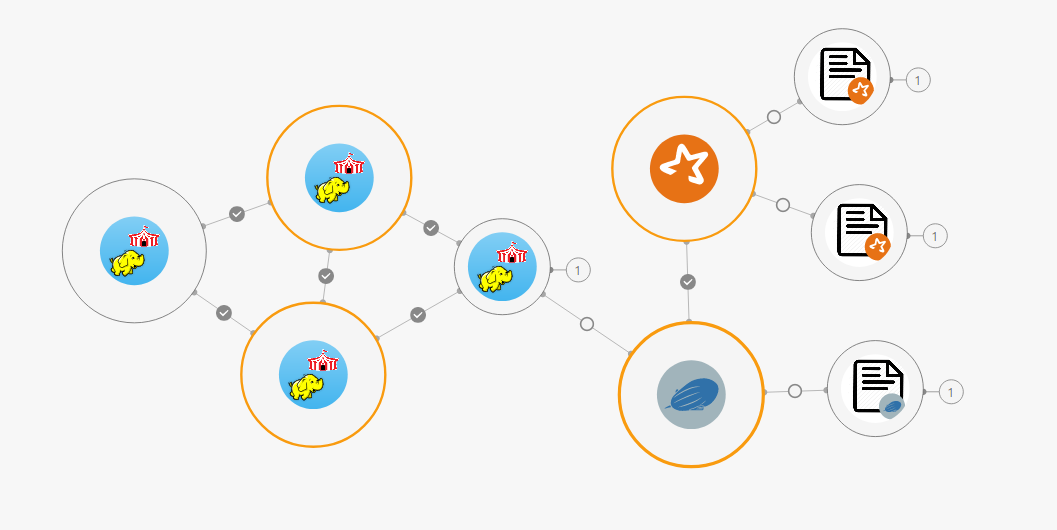
Above we see the deployment of a spark bundle with some custom spark jobs and a custom Notebook for Zeppelin.
This bundle contains a number of services:
Spark
- Spark is running with 2 spark jobs that will first retrieve the information from a data source and afterwards transform it into a smaller dataset.
Hadoop
- Hadoop is running and has a relationship with Zeppelin. As an example here, Zeppelin is used to visualize data from meteorite impacts since the year 2000. Zeppelin uses HDFS to store data.
- The Hadoop service component consists of different services:
- Hadoop name node
- Hadoop resourcemanager
- 3 Hadoop slaves
The Zeppelin Notebook has a relation with spark and Hadoop. Zeppelin retrieves data from HDFS and makes it possible to query the data. As a result, we can visualize the dataset on Zeppelin with a custom notebook as shown below. This Notebook will already load the data so you can immediately start writing your own queries.
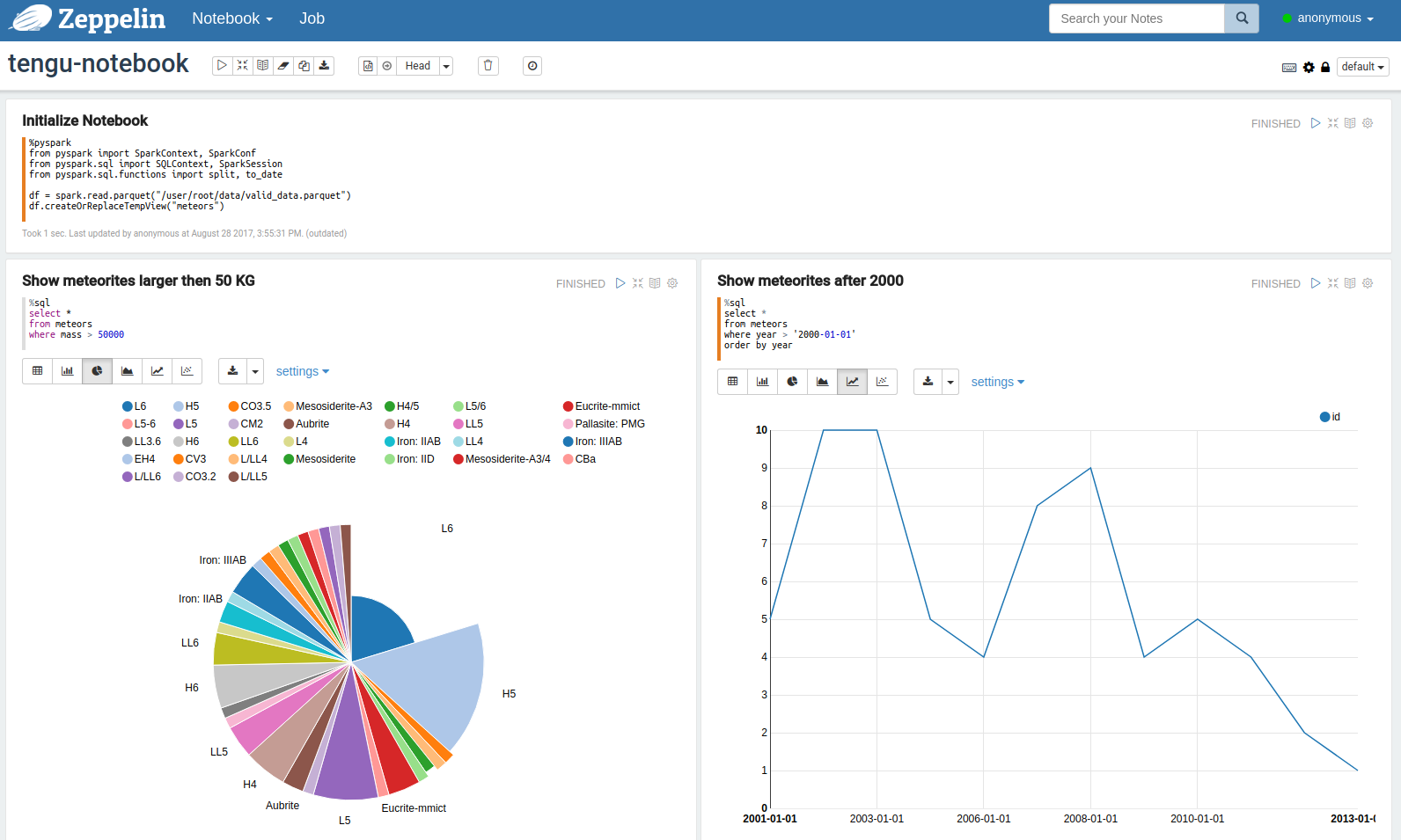
The deployment of the complete bundle took Tengu about 25 minutes. Tengu makes complex Big Data deployments almost "foolproof". As a result, there is no more need to manually install, configure or integrate the technologies required. This allows the data scientist to immediately focus on conceptualization, business intelligence and less on operations.


